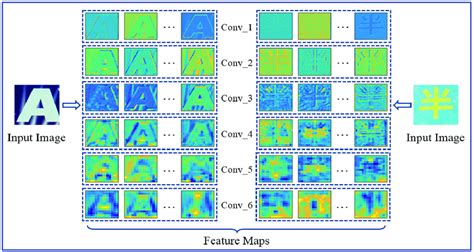
注:上面只是示意图,实际书稿中建议用自绘或重画的简洁示意图替换。
3.2 视觉特征与表示学习(节选)
本节聚焦“视觉 backbone 究竟在学什么”。从卷积的层级特征,到 Vision Transformer 的 patch-token 表示,再到自监督预训练与迁移使用方式,这一节是后面 VLM / VLA 模型视觉部分的“放大镜”。
3.2.1 卷积特征与层级表示直觉
学习导航
- 本章主题:3.2.1 卷积特征与层级表示直觉
- 前置知识:建议先完成第 2 章基础网络与训练技巧。
- 建议用时:65-85 分钟
- 阅读顺序:先看概念框架,再看公式/代码,最后做自测。
卷积神经网络(CNN)已经被证明会自动学习出从边缘、纹理到物体部件、完整对象的分层表征,与生物视觉皮层中从 V1 到 IT 的层级处理有相似之处。(arXiv) 对机器人来说,这意味着:同一个相机画面,在不同层中被编码成不同抽象层级的信息,为后续抓取、导航、场景理解提供基础。
3.2.1.1 卷积网络的层级特征
可以把卷积核看成一块块可学习的小“模板”,在图像上滑动,检测某种局部模式是否出现。早期层的模板非常“原始”,后期层变得“语义化”。
+低层特征:边缘和纹理
在第一、二层卷积中,可视化滤波器时,经常能看到“Gabor 滤波器”式的条纹、斑点、方向性边缘等。(arXiv) 对机器人来说,这一层类似回答“这里有一条明暗边界”“这里有一段重复纹理”的问题,有助于后续识别桌沿、物体轮廓。
+中层特征:局部图形和部件
随着网络加深,卷积层的感受野(能“看到”的输入区域)逐渐变大,中层卷积核开始响应更复杂的局部结构,比如圆形角落、T 字交界、物体的一部分(杯把、车轮、门把手等)。这些特征已经脱离“几何原始元素”,开始向“物体部件”靠拢。(SPIE Digital Library)
+高层特征:对象和类别级模式
在靠近分类头的高层卷积中,特征往往与具体类别强相关,例如“狗头”“键盘区域”“车前脸”等高度语义化的激活。Zeiler & Fergus 的可视化工作表明,高层 feature map 上,一整块区域常常只在特定类别图像中被激活。(arXiv)
【插图占位 3.2.1-1】 “CNN 不同层的卷积核与激活可视化”: 左侧为浅层卷积核(类似边缘检测器);中间为中层对纹理与局部形状的响应;右侧为高层对物体部件/对象的响应。用一张输入图(如桌面上有杯子)对应三层 feature map 激活。
在具身智能场景中,可以这样理解:当机械臂视觉系统通过 ResNet 看一张桌面图像时,早期层主要检测各种边缘和纹理(桌沿、物体阴影),中层开始形成“杯子边缘”“盒子角”等部件特征,高层则直接形成“杯子”“蓝色盒子”等对象级特征,供上层任务(如“抓起杯子”)使用。
3.2.1.2 特征图(Feature Map)
卷积操作对输入图像进行处理后,输出的是一个多通道的张量,通常记作大小为 \(H \times W \times C\):
- \((H, W)\):空间维度,对应图像在当前层的分辨率;
- \(\displaystyle C\):通道数,每个通道就是一个feature map,代表某个卷积核在整幅图上的“响应强度图”。
可以把 feature map 看成:“对于这一种视觉模式,每个像素位置匹配的程度是多少”。例如某个通道专门响应“垂直边缘”,那在所有垂直物体边缘的位置,这个通道的值会比较大。
随着网络前进,卷积步长和池化层会逐步降低 \((H,W)\),而提高通道数 \(\displaystyle C\)。这意味着:
+空间分辨率下降:单个激活对应的物理区域更大; +通道维表达能力增强:每一个空间位置上,C 维向量可以编码非常丰富的语义。
这样的结构自然形成了多尺度特征金字塔:浅层 feature map 分辨率高,适合描述精细边界和小物体;深层 feature map 分辨率低、语义强,适合理解“这块区域大致是什么东西”。
【插图占位 3.2.1-2】 “Feature Map 尺寸变化示意”: 画出一张输入图像,经过多层卷积+池化后 feature map 的形状从 \(224\times224\times3\) 变为 \(112\times112\times64\)、\(56\times56\times128\)…直至 \(7\times7\times2048\),用不同颜色方块表示不同通道。
在机器人应用中,这些 feature map 通常不会直接显示,而是输入到检测头、抓取预测头或下游 Transformer 中,作为视觉语义的“压缩表达”。
3.2.1.3 层级表示直觉
总结起来,卷积网络的层级表示有几个直观要点:
1.从局部到全局 早期层只“看见”局部几像素,后期层的感受野可以覆盖图像中很大的区域甚至全图,逐步整合上下文。 2.从具体到抽象 表征从“这有条边”“这里有条纹理”逐渐演化为“这个区域像是一个杯子”“这大概是桌面的一角”。这种从低级特征到高级语义的抽象,与认知科学中人类视觉皮层的层级处理趋势相似。(ScienceDirect) 3.局部平移不变性和结构先验 卷积核在整幅图上共享权重,让网络天然对小范围平移具有不变性。这种强归纳偏置使 CNN 在中等规模数据集上非常高效、稳定,但也导致其对更复杂的长程关系(如远处两个物体之间的关系)建模能力有限。
对具身智能来说,这意味着:如果任务主要依赖局部形状与纹理(例如检测桌沿、防止跌落、识别可抓取边缘),卷积 backbone 通常已经足够;而当任务涉及复杂全局关系(例如“把桌面最左边的杯子移到靠近门的那边”),我们更希望有能力建模“全局 patch 之间关系”的结构——这正是 Vision Transformer 要解决的问题。
3.2.2 视觉 Transformer(ViT)的基本结构
Vision Transformer(ViT)直接把图像视为一串“视觉 token”,用 Transformer 编码器处理,从而将 NLP 中已经验证有效的全局自注意力机制引入视觉。(arXiv)
3.2.2.1 图像分块
经典 ViT 的第一步是图像分块(patch embedding):
- 给定一幅大小为 \(H \times W \times C\) 的图像;
- 使用固定大小的 patch(如 \(P \times P\))将图像划分为 \(N = \frac{HW}{P^2}\) 个不重叠的小块;
- 每个 patch 展平为长度 \(P^2 C\) 的向量,并通过一个线性层投影到 \(\displaystyle D\) 维,得到一个 token;
- 所有 patch token 组成长度为 \(\displaystyle N\) 的序列,再加上一个 learnable 的 class token,总长度为 \(N+1\);
- 再加上可学习的位置编码,以保留 patch 的空间位置信息。(arXiv)
【插图占位 3.2.2-1】 “ViT patch embedding 架构”: 左侧是一张输入图像,被切成若干 \(P\times P\) 的小 patch;每个 patch 展平后通过线性层映射为 D 维向量;所有 patch token 与一个 class token 拼接成序列,并加上位置编码输入 Transformer encoder。
在机器人视角下,可以理解为:摄像头拍到的画面首先被离散为几十到上百个“小视野格子”,每个格子由一个向量描述。后续的自注意力层决定这些格子之间如何互相“交流”。
3.2.2.2 自注意力在图像中的应用
在 ViT 中,Transformer 编码器对 token 序列应用多层自注意力(self-attention):
- 每个 patch token 通过线性变换产生 Query / Key / Value;
- 每个 patch 的 Query 与所有 patch 的 Key 计算相似度,经 softmax 得到注意力权重;
- 使用权重对 Value 做加权和,得到融合了全局信息的新表示。(d2l.ai)
直觉上,这相当于:每个 patch 决定“应该向哪些其他位置要信息”。例如在桌面场景中:
- 表示“杯子”的 patch 可能会关注桌面边缘(判断杯子是否在边缘,是否安全);
- 表示“目标盒子”的 patch 会关注周围障碍物 patch,辅助规划路径。
多头注意力让不同“注意力头”在不同子空间内学习不同的关注模式:有的头关注近邻局部纹理,有的头捕捉对称、重复结构,有的头专门建模远距离物体间的关联。(wikidocs.net)
与 CNN 相比,自注意力有两大关键差异:
+显式全局建模:每个位置可以直接与任意位置交互,而不需要堆叠许多局部卷积才能间接感知远处; +归纳偏置更弱:不强假设局部平移不变性,网络在足够数据上可以学习更丰富的模式,但在小数据集上也更容易过拟合或训练不稳定。
3.2.2.3 ViT 特点
综合来说,ViT 作为视觉 backbone 具有以下特点:(arXiv)
1.全局视野与强表示能力
自注意力使得 ViT 在每一层就能获取全局信息,对复杂布局、长程关系建模有天然优势。在大规模预训练(如 ImageNet-21k 或图文对齐数据)下,ViT 在分类、检测、分割等任务上已经超越或媲美同规模 CNN。
2.对数据量敏感
由于缺乏 CNN 那种强的局部归纳偏置,ViT 在小数据集从头训练通常表现不佳,需要:
- 借助大规模有监督或自监督预训练;
- 或在结构中引入层次化、局部窗口(如 Swin Transformer 一类)。
3.与自监督方法高度契合
ViT 的“token 化”结构与掩码建模(MAE 等)天然匹配,在自监督框架下表现尤为突出,这是后续 3.2.3 将重点展开的内容。(arXiv)
4.对机器人应用的影响
- 在算力足够(如云端推理或高性能边缘设备)且数据丰富时,可使用 ViT/层次 Transformer backbone 作为机器人视觉主干,更好地理解复杂场景;
- 在实时性、算力严苛的场景中,往往采用轻量化 Transformer 变体,或与 CNN 混合使用,以兼顾性能与速度。
3.2.3 自监督视觉表征(对比学习、MAE 等基本思想)
对于具身智能而言,最稀缺的不是图像,而是高质量标注和示教。机器人可以 24 小时拍视频,但人类不可能 24 小时在旁边标注。这使得“如何利用大量未标注视觉数据学习通用表示”成为关键问题,自监督学习正是目前最主流的答案之一。(SpringerLink)
3.2.3.1 对比学习
对比学习(contrastive learning)的核心想法是:把“同一个事物的不同观察”拉近,把“不同事物”拉远。在视觉自监督中,常见做法是“实例判别(instance discrimination)”:每张图像被视为自己的“类别”。(CVF开放获取)
典型框架(SimCLR、MoCo 等)的基本流程:
- 对同一张原始图像做两次随机数据增强(裁剪、翻转、颜色抖动、模糊等),得到两张“视角不同”的图像;
- 使用共享参数的编码器(CNN 或 ViT)分别将这两张图像映射到特征向量;
- 通过一个小的投影头(MLP)映射到对比空间;
- 设计对比损失(如 InfoNCE):
- 把这两个来自同一图像的向量视为“正样本对”;
- 与 batch 中其他图像的向量作为“负样本”;
- 优化目标是让正样本对在特征空间距离更近,负样本更远。
直觉上,相当于告诉网络:“即便这杯子的姿态、光照改变,它在特征空间也应该是同一个‘点附近’。” 训练完成后,编码器就学到了一种对常见变化(旋转、光照、轻微遮挡)不敏感、但对语义差异敏感的特征。
在机器人场景中:
- 正样本可以是同一次操作的不同帧,或同一物体在不同位置、不同抓取阶段的图像;
- 负样本是其他物体或其他任务场景;
这样,机器人在没有任何“类别标签”的情况下,就能学会“哪些图像属于同一事物或同一过程”,为后续的抓取预测或策略学习提供基础特征。
3.2.3.2 掩码图像建模(MAE)
对比学习强调“区分”,而**掩码图像建模(Masked Image Modeling, MIM)**更强调“重建”。其中影响力最大的工作之一就是 MAE(Masked Autoencoders)。(arXiv)
MAE 的关键思想:
- 仍然基于 ViT 的 patch 表示,将图像切成若干 patch; 2.随机遮挡大部分 patch(例如 75%),只保留少量可见 patch;
- 编码器(ViT encoder)只处理可见 patch,生成其高维表示;
- 将可见 patch 表示与位置编码、掩码标记一起输入一个轻量解码器;
- 解码器的任务是重建被遮挡部分的像素(或某种压缩形式,如低分辨率图)。
重要特性有两点:
+极高遮挡比例:迫使模型必须真正理解全局结构,而不是简单“补纹理”; +编码器轻负载:只对可见 patch 计算自注意力,大幅节约计算,特别适合大规模预训练。(arXiv)
直觉上,MAE 要求模型回答的问题是:“在只看见一小部分图像补丁的情况下,这张图合理的完整样子是什么?” 这使得模型必须学到:
- 物体典型形状(杯子大致是圆柱、桌子是平面等);
- 背景与物体的相互约束关系;
- 不同 patch 之间的纹理、颜色、结构一致性。
在机器人应用中,遮挡是常态——机械臂自己会挡住部分视野,桌面物体会相互遮挡。通过 MAE 预训练的 ViT 在面对大面积遮挡、视角变化时,往往比纯监督训练的模型更稳健。后续还有很多基于 MIM 的变体,扩展到视频、点云等模态,在这里不展开。(ScienceDirect)
【插图占位 3.2.3-1】 “MAE 自监督框架”: 左侧为原始图像和其 patch;中间展示随机遮挡的 patch(大面积灰块);右侧是编码器只处理可见 patch,解码器重建完整图像的流程图。
3.2.3.3 自监督的意义
自监督视觉学习对具身智能的意义,并不仅仅是“省标签”,更深层的价值在于:
1.大幅提高数据利用率
现实中很容易收集到“机器人看到的一切”:摄像头视频、深度图、点云等。但完整标注每一帧中的物体、语义、动作几乎不可能。自监督允许我们用这些原始数据构建大规模预训练语料库,让视觉 backbone 从“无标签的观察”中学习世界的结构。(SpringerLink)
2.得到更通用、与任务无关的表示
和在单一标注任务(比如 ImageNet 分类)上训练得到的特征相比,对比学习和 MAE 这种预训练方式往往给出更“面向世界”的表征——它们捕捉到的是一般性的视觉规律,而不是某个数据集里特定类别的边界。因此,在目标检测、分割、3D 理解乃至机器人策略学习上迁移时,都更容易适配。
3.为世界模型和长期规划打基础
重建式自监督(如 MAE)和时序预测式自监督(预测下一帧、未来轨迹)本质上都是在学习“如果世界缺了一部分信息,我能不能根据上下文补完”的能力。这种能力对于构建具身智能的“世界模型”至关重要,是后续章节(例如 9.3、12.1)要讨论的核心方向之一。
4.实际工程中的策略
对一个真实机器人平台,常见做法是:
- 长时间录制未标注视频,构建视觉自监督预训练数据;
- 先用对比学习或 MAE 预训练视觉 backbone;
- 再用少量示教数据、标注任务数据微调到具体操作任务上(抓取、分类、可抓取检测等)。
这种“先学看,再学做”的范式,在多模态 VLM/VLA 模型中会进一步扩展为“先学看 + 听(视觉 + 语言),再学做(动作)”。
3.2.4 视觉 Backbone 的选择与迁移(ResNet、ViT 等)
在具身系统中,视觉 backbone 不只是一个“分类器的前半部分”,而是整个系统对世界的主要感知入口。选择何种 backbone,以及如何迁移预训练权重,对最终性能、实时性、部署成本都有直接影响。
这里重点讨论两类主力骨干:ResNet(典型 CNN)与 ViT(典型 Transformer),以及它们在迁移学习中的常见用法。
3.2.4.1 ResNet
ResNet(Residual Network)的核心思想是引入残差连接,即让每一层只需要学习相对于输入的“增量”。这极大缓解了深层网络中的梯度消失问题,使得 50 层、101 层甚至更深的 CNN 训练变得可行。(SPIE Digital Library)
从视觉 backbone 的角度看,ResNet 有几个工程上非常重要的特点:
1.强归纳偏置与稳定性能
标准的卷积+池化+残差结构,使得 ResNet 在中等规模数据集上具有极高的收敛稳定性和泛化能力。即便没有大规模自监督预训练,直接在任务数据上微调也常能得到不错的结果。
2.成熟的工具链与硬件友好性
各种深度学习框架和推理引擎对卷积操作高度优化,在嵌入式 GPU、加速器上都有现成的高效实现;因此 ResNet 类 backbone 在移动机器人、嵌入式机械臂上非常常见。
3.多尺度特征易于复用
ResNet 的分层结构天然适合构造特征金字塔(如 FPN),用于目标检测、实例分割等任务——这些任务又恰恰是机器人抓取、障碍检测的基础模块。(SPIE Digital Library)
在具身智能的实践中,一条常见经验是:
+初期实验 / 小规模项目:优先选用 ResNet-18 / 34 等轻量骨干,保证训练和部署简单、鲁棒; +性能要求更高:可升级到 ResNet-50 / 101 加 FPN,用于精度更高的场景理解,再将结果提供给上层 VLA 决策模块。
3.2.4.2 ViT
相比之下,ViT 系列 backbone 更“现代”,也更依赖大规模预训练。当前主流开源模型(如 vit-base-patch16-224 等)通常先在 ImageNet-21k 等大数据集上预训练,再在 ImageNet-1k 上微调。(Hugging Face)
作为视觉 backbone,ViT 有几方面的特点:
1.全局建模能力
利用自注意力,ViT 对全图 patch 之间的关系进行显式建模,尤其有利于需要理解复杂场景关系的任务,例如:
- 判断多个物体之间的相对位置(哪一个“更靠近门口”);
- 推理遮挡关系(哪个物体被挡住、相对深度)。
2.与图文预训练、VLM 的天然适配
ViT 常被用作图文对齐模型(如 CLIP)中的视觉编码器,学习到的特征与语言空间对齐良好,非常适合直接用作机器人 VLM/VLA 模型的视觉 backbone。(arXiv)
3.在大数据下优于 CNN,小数据下需谨慎
多项比较研究显示,当训练和预训练数据足够大时,ViT 在分类、识别类任务上的表现可以显著超越或至少不弱于同规模 ResNet。(arXiv) 但在小数据集、从头训练或迁移数据分布与预训练差异很大时,原始 ViT 可能难以训练稳定,这时需要:
- 使用 MAE/对比学习等自监督权重;
- 或采用带卷积前端、窗口注意力的改进架构(如 Swin、ConvNeXt 等)。
在具身智能系统中,常见的一种组合是:语言–视觉对齐用 ViT(或其变体),低层几何理解和实时感知仍以 CNN 为主,二者通过特征融合或多任务训练结合起来。
3.2.4.3 迁移学习
无论使用 ResNet 还是 ViT,视觉 backbone 在机器人任务中几乎总是以“预训练 + 迁移”的方式出现,而不是从零开始训练。迁移学习通常包含几个关键决策:(arXiv)
1.选择预训练来源
- 经典监督预训练:如 ImageNet 分类;
- 自监督预训练:对比学习(SimCLR、MoCo、DINO 等)、MAE 等;
- 多模态预训练:图文对齐模型(CLIP 风格)、视频自监督等。
对机器人来说,多模态和自监督预训练往往更有优势,因为它们捕捉到的是更通用的世界结构,而不是某个特定分类任务。
2.“冻结 vs 全量微调 vs 参数高效微调” +冻结特征 + 训练任务头:适合数据较少、算力有限、对性能要求不极致的场景; +全量微调:适合数据相对充足、希望 backbone 充分适应特定场景(特殊光照、视角、相机)的情况; +参数高效微调(Adapter / LoRA 等):在不修改大部分预训练权重的前提下,仅训练少量插入模块,达到较好适应能力,又控制了训练成本;这与第 2.5.3 节中语言模型微调的思想完全一致。 3.根据任务和资源选择 backbone 类型
一个实用的经验表,可以帮助在具身智能项目中快速做出初步选择:
+小数据集 + 强实时性 + 嵌入式设备 → 轻量 CNN(ResNet-18/34、MobileNet 等),使用 ImageNet 或自监督预训练权重,冻结大部分层,仅微调最后几层和任务头。 +中等数据规模 + 单一场景(固定工位、固定相机) → 可以使用更深的 ResNet 或轻量 ViT / Swin;优先使用自监督预训练权重(SimCLR/MoCo/MAE)以提高数据效率。 +大规模多场景数据 + 多任务机器人平台 → 优先使用 ViT 或层次 Transformer backbone(如 Swin)、甚至直接采用 CLIP-ViT 或 MAE-ViT 作为视觉模块,与大语言模型共同组成 VLM / VLA 系统。在这种情况下,视觉编码器的能力将成为整个系统泛化能力的关键瓶颈之一。
【插图占位 3.2.4-1】 “视觉 backbone 迁移流程”: 画出一个从左到右的流程: “大规模预训练数据(ImageNet/图文/未标注视频)” → “预训练视觉 backbone(ResNet/ViT)” → “加入机器人特定任务头(检测、抓取预测等)” → “在机器人任务数据上微调(可选:冻结部分层、Adapter 微调)”。
在后续章节中,视觉 backbone 会以多种角色重复出现:在第 4 章中作为图文对齐模型的一部分,在第 8 章中作为 VLA 统一模型的视觉输入模块。读者理解了本节中 CNN 层级特征与 ViT patch-token 表示、自监督预训练与迁移学习的基本思路,就具备了“读懂后面模型结构图中视觉那一坨方块究竟干什么”的能力。接下来,我们会在 3.3 节进一步将 2D 视觉表示延伸到 3D 场景理解,为机器人在物理世界中行动铺路。
本章小结与自测
三行小结
- 本章解释视觉信息如何转成机器人可用表征。
- 关键在于任务定义、表示学习与工程约束并行考虑。
- 学完后应能为任务选择合理视觉输入与评测指标。
检查题
- 用你自己的话总结本章最核心的一个公式/机制。
- 给出一个“如果要落地到项目里,你会怎么用”的具体例子。
常见误区
- 只追求 backbone 大小,忽略任务匹配。
- 忽略数据标注噪声。
- 指标选择与任务目标不一致。
公式到代码(最小示例)
def iou(box_a, box_b):
xa1, ya1, xa2, ya2 = box_a
xb1, yb1, xb2, yb2 = box_b
inter_w = max(0, min(xa2, xb2) - max(xa1, xb1))
inter_h = max(0, min(ya2, yb2) - max(ya1, yb1))
inter = inter_w * inter_h
area_a = (xa2 - xa1) * (ya2 - ya1)
area_b = (xb2 - xb1) * (yb2 - yb1)
union = area_a + area_b - inter
return inter / union if union > 0 else 0.0
本章外部参考(集中)
- arXiv
- SPIE Digital Library
- ScienceDirect
- arXiv
- d2l.ai
- wikidocs.net
- arXiv
- SpringerLink
- CVF开放获取
- ScienceDirect
- Hugging Face
- arXiv
- 本章其余链接可在正文中按上下文继续查阅。